Introduction to Batch Processing
Some enterprise applications contain tasks that can be executed without user interaction. These tasks are executed periodically or when resource usage is low, and they often process large amounts of information such as log files, database records, or images. Examples include billing, report generation, data format conversion, and image processing. These tasks are called batch jobs.
Batch processing refers to running batch jobs on a computer system. Java EE includes a batch processing framework that provides the batch execution infrastructure common to all batch applications, enabling developers to concentrate on the business logic of their batch applications. The batch framework consists of a job specification language based on XML, a set of batch annotations and interfaces for application classes that implement the business logic, a batch container that manages the execution of batch jobs, and supporting classes and interfaces to interact with the batch container.
A batch job can be completed without user intervention. For example, consider a telephone billing application that reads phone call records from the enterprise information systems and generates a monthly bill for each account. Since this application does not require any user interaction, it can run as a batch job.
The phone billing application consists of two phases: The first phase associates each call from the registry with a monthly bill, and the second phase calculates the tax and total amount due for each bill. Each of these phases is a step of the batch job.
Batch applications specify a set of steps and their execution order. Different batch frameworks may specify additional elements, like decision elements or groups of steps that run in parallel. The following sections describe steps in more detail and provide information about other common characteristics of batch frameworks.
Steps in Batch Jobs
A step is an independent and sequential phase of a batch job. Batch jobs contain chunk-oriented steps and task-oriented steps.
-
Chunk-oriented steps (chunk steps) process data by reading items from a data source, applying some business logic to each item, and storing the results. Chunk steps read and process one item at a time and group the results into a chunk. The results are stored when the chunk reaches a configurable size. Chunk-oriented processing makes storing results more efficient and facilitates transaction demarcation.
Chunk steps have three parts.
-
The input retrieval part reads one item at a time from a data source, such as entries on a database, files in a directory, or entries in a log file.
-
The business processing part manipulates one item at a time using the business logic defined by the application. Examples include filtering, formatting, and accessing data from the item for computing a result.
-
The output writing part stores a chunk of processed items at a time.
Chunk steps are often long-running because they process large amounts of data. Batch frameworks enable chunk steps to bookmark their progress using checkpoints. A chunk step that is interrupted can be restarted from the last checkpoint. The input retrieval and output writing parts of a chunk step save their current position after the processing of each chunk, and can recover it when the step is restarted.
Figure 58-1 shows the three parts of two steps in a batch job.
Figure 58-1 Chunk Steps in a Batch Job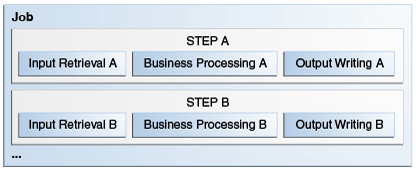
-
For example, the phone billing application consists of two chunk steps.
-
In the first step, the input retrieval part reads call records from the registry; the business processing part associates each call with a bill and creates a bill if one does not exist for an account; and the output writing part stores each bill in a database.
-
In the second step, the input retrieval part reads bills from the database; the business processing part calculates the tax and total amount due for each bill; and the output writing part updates the database records and generates printable versions of each bill.
This application could also contain a task step that cleaned up the files from the bills generated for the previous month.
Parallel Processing
Batch jobs often process large amounts of data or perform computationally expensive operations. Batch applications can benefit from parallel processing in two scenarios.
-
Steps that do not depend on each other can run on different threads.
-
Chunk-oriented steps where the processing of each item does not depend on the results of processing previous items can run on more than one thread.
Batch frameworks provide mechanisms for developers to define groups of independent steps and to split chunk-oriented steps in parts that can run in parallel.
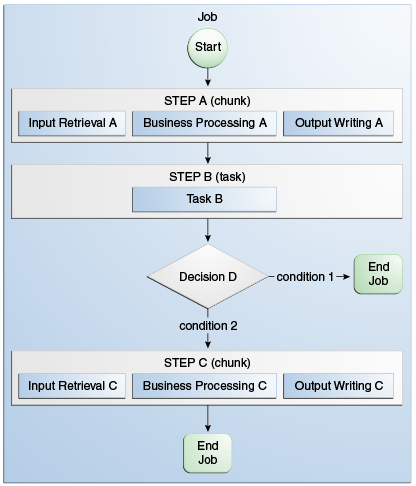
Status and Decision Elements
Batch frameworks keep track of a status for every step in a job. The status indicates if a step is running or if it has completed. If the step has completed, the status indicates one of the following.
-
The execution of the step was successful.
-
The step was interrupted.
-
An error occurred in the execution of the step.
In addition to steps, batch jobs can also contain decision elements. Decision elements use the exit status of the previous step to determine the next step or to terminate the batch job. Decision elements set the status of the batch job when terminating it. Like a step, a batch job can terminate successfully, be interrupted, or fail.
Figure 58-2 shows an example of a job that contains chunk steps, task steps and a decision element.
Batch Framework Functionality
Batch applications have the following common requirements.
-
Define jobs, steps, decision elements, and the relationships between them.
-
Execute some groups of steps or parts of a step in parallel.
-
Maintain state information for jobs and steps.
-
Launch jobs and resume interrupted jobs.
-
Handle errors.
Batch frameworks provide the batch execution infrastructure that addresses the common requirements of all batch applications, enabling developers to concentrate on the business logic of their applications. Batch frameworks consist of a format to specify jobs and steps, an application programming interface (API), and a service available at runtime that manages the execution of batch jobs.